
量子位 报道 | 公众号 QbitAI
深度强化学习,可以用来学走路了。
Agility Robotics的双足机器人Cassie,这个没有上半身的机器人,就靠着深度强化学习学会了更灵活的使用自己身体的唯二器官:左腿,和右腿。
看,它可以正常的往前走。

还能大步快走,差点就跑起来了。

作为一个传送带运动爱好者,万一踩到了传送带的边缘也不会两脚劈叉,而是稳稳的继续前行。

甚至,倒着走也一样稳。

或者学习一下螃蟹,横行霸道。

这种时候,不怀好意的人类就开始欺负它了,拿木棍戳它的小肚腩。

站的稳稳地,Cassie没有一点点要倒下的意思。
既然戳肚子正前方没有反应,那我们换个角度,戳肚子的侧面,大概是“腰子”的位置。

稍稍歪了一下,但影响不大,Cassie该怎么走还是怎么走。
肚子看来干扰不了,那就干扰脚底,放一块木板,绊倒它。

可惜如意算盘没能实现,Cassie一脚踩在木板上,稍微晃了晃,依然稳步前行,甚至还回踩了一脚。
学走路进行时
新的行走技能,要归功于加拿大不列颠哥伦比亚大学计算机系和俄勒冈州立大学动力机器人实验室两所机构。
让Cassie学会行走,需要用到强化学习和模仿学习(Imitation Learning)。
强化学习解决马尔可夫决策过程( Markov Decision Process, MDP)的最优策略,需要用到策略梯度算法;而模仿学习则需要解决参数策略问题。
之后,需要用到关键算法DASS来搞定数据集。每次连续设计迭代时重新定义奖励函数,用确定性行动随机状态(Deterministic Action Stochastic State,DASS)元组来表征策略。

之后,将DASS于强化学习、模仿学习结合在一起,为机器人设定策略。
现在需要在Cassie机器人上实验了。
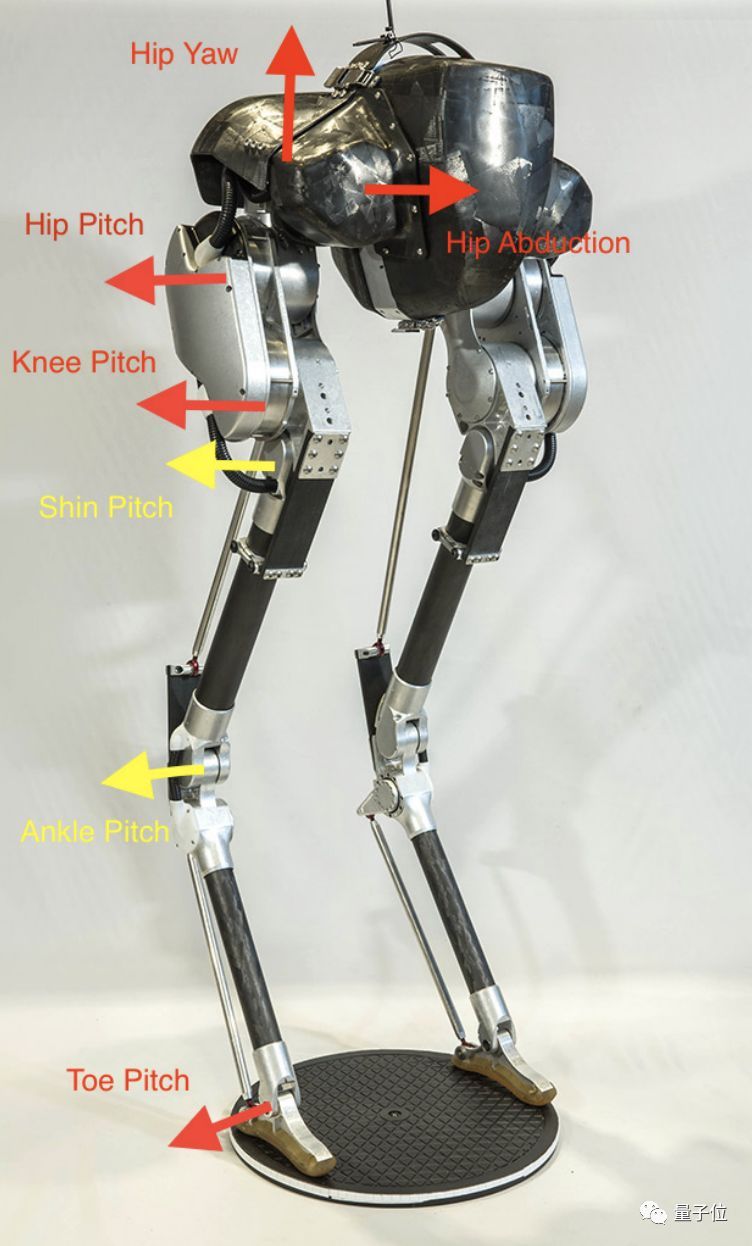
Cassie双足机器人身高大约1米,体重31千克,两条腿上有复杂的传动机制,红色箭头都是主动关节,黄色的箭头都是被动关节。
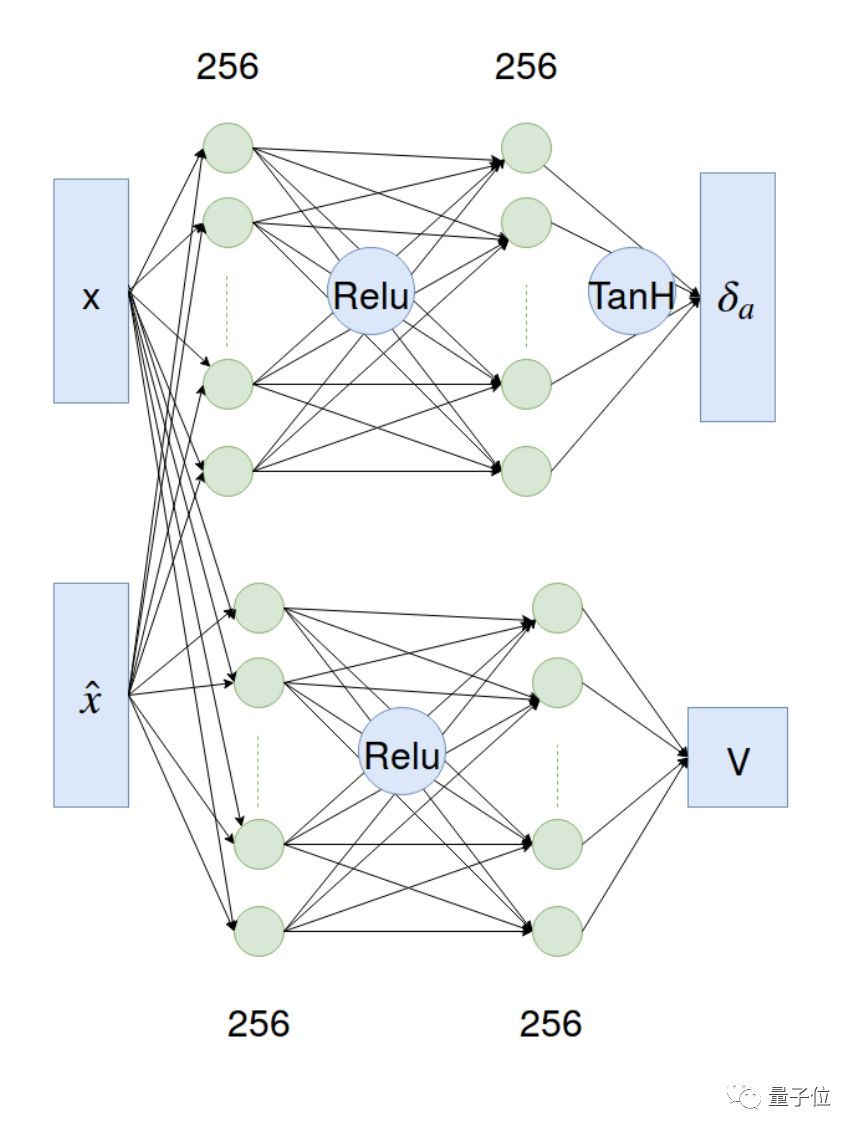
需要在神经网络上进行参数化策略优化,这里用到了actor-critic算法和MuJoCo模拟器。
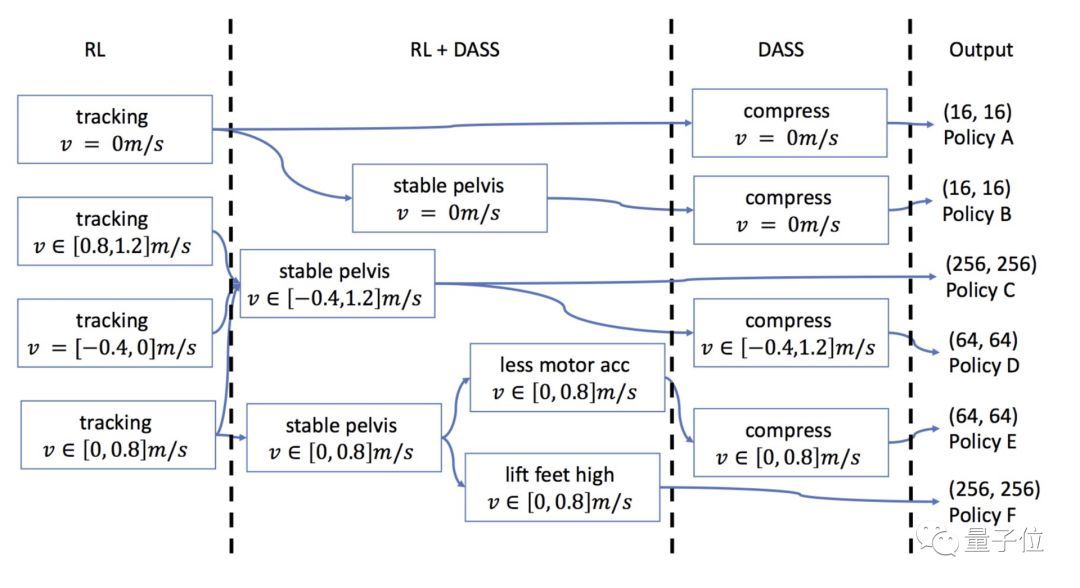
策略设计过程则是依靠四个基于追踪的策略的起始点。 DASS样本根据箭头的方向,从一个策略传递到下一个策略。
实际操作中,需要先训练几个初始策略,之后参考机器人的运动状态和需要达到的运动速度进行调整,这里只需要5~10k的小数据集就能实现变速行走策略。
最后,就可以让机器人跑起来了。Cassie机器人需要和计算机联网,操作过程中研究者们用到了Ubuntu系统和PyTorch框架来执行学习策略。
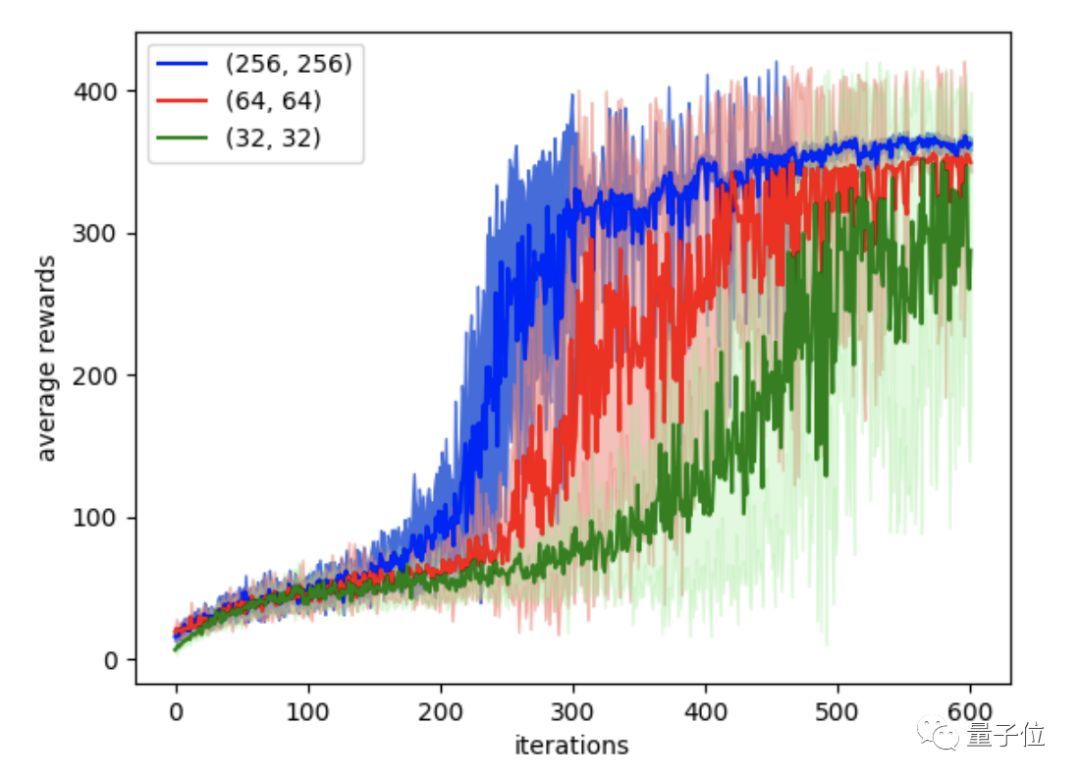
实验之后,可以看出使用更大的神经网络,就可以更快的产出更稳定的策略,比如图中的蓝色线条要明显优于红色和绿色。
本文首发于微信公众号:量子位。文章内容属作者个人观点,不代表和讯网立场。投资者据此操作,风险请自担。

